.svg)

Starbridge Engineering Labs: How We Built a Flexible Release Process

Every growing engineering team hits the same wall: a single staging environment that becomes a bottleneck. One developer is testing a feature, another needs to demo for a stakeholder, and a third is verifying a hotfix — all competing for the same environment. Deployments queue up, context-switching multiplies, and velocity drops.
At Starbridge, we solved this with a release process built around parallel, on-demand environments. Any engineer can deploy any branch to its own isolated environment in seconds, test it independently, and merge to production with confidence. No waiting, no coordination overhead, no shared-environment drama. Here is how it works.
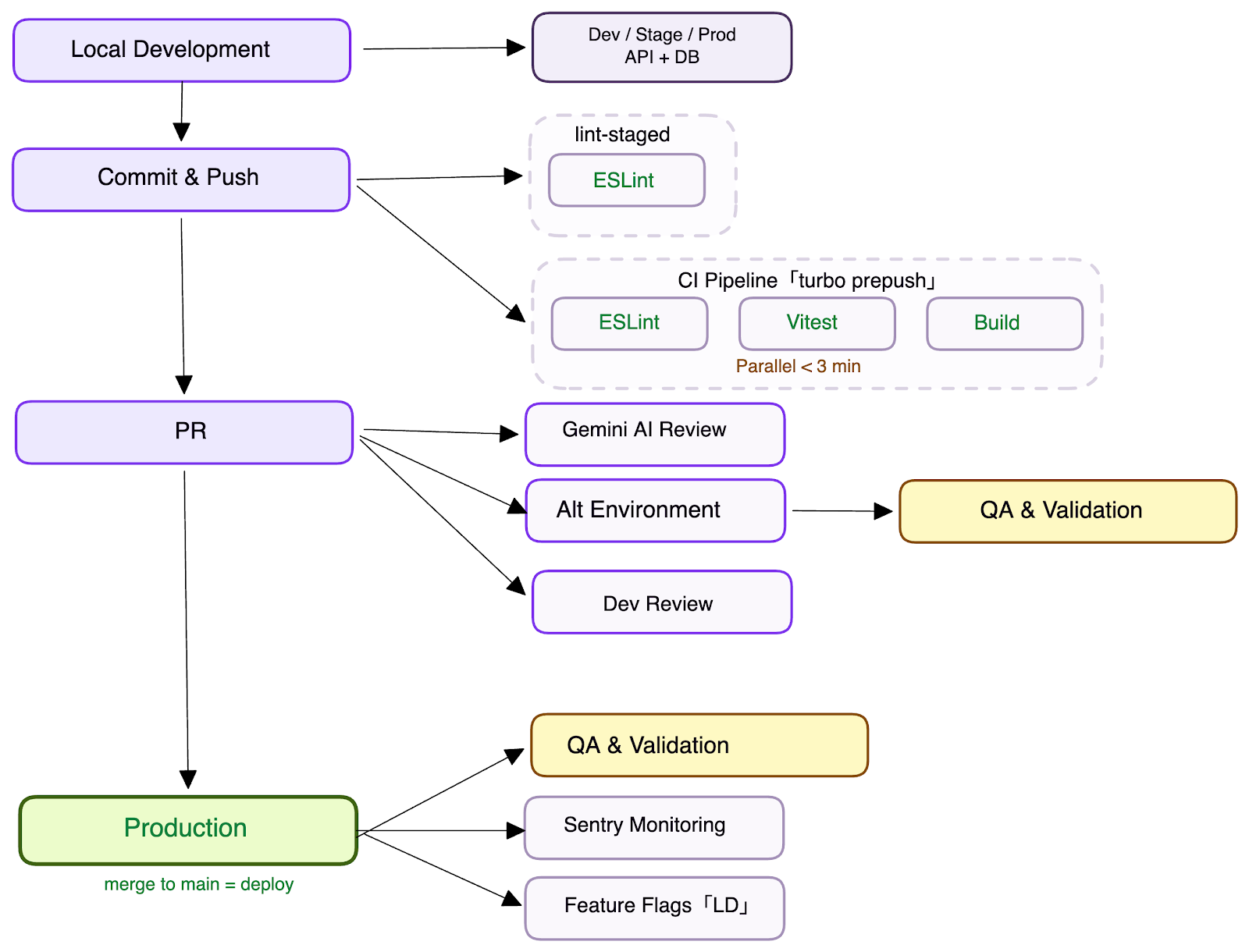
The Stack & Monorepo Structure
Our codebase is a Yarn 4 monorepo orchestrated by Turborepo. It contains two applications — a Dashboard (Vite + React 19) and a Public site (Next.js 15) — alongside shared packages: a design system (@repo/sb.ds), shared types (@repo/types), utilities (@repo/utils), and constants.
The key insight: apps and packages live together and ship together. A single pull request can update a shared component in @repo/sb.ds and the dashboard feature that consumes it. CI validates everything as one unit. There is no cross-repo coordination, no version-pinning dance, no "wait for the library release before you can merge your feature." One repo, one truth.
The stack is deliberately chosen to maximize reuse and minimize code that needs to be written — and therefore reviewed. Tailwind CSS eliminates custom stylesheets entirely; styles are co-located with markup, so reviewers see exactly what a component looks like without jumping between files. React Query (useQuery / useMutation) replaces hand-rolled data fetching, caching, and state synchronization with declarative hooks — no boilerplate reducers, no manual cache invalidation. Our shared component library (@repo/sb.ds) provides a consistent set of primitives and compositions that teams reach for instead of building from scratch. The result: PRs are smaller, diffs are clearer, and reviewers spend their time on business logic rather than plumbing.
Local Development
Before code even reaches a PR, developers need a fast local feedback loop. We run the dashboard locally against remote backend environments with a single command: yarn dev, yarn stage, or yarn prod. Each command points the local frontend at the corresponding backend API, giving developers immediate access to real data — the same data QA and product teams see. This makes it easy to reproduce bugs against production state or test a feature against staging data without spinning up any local services.
Under the hood, the app runs on Vite's dev server, which is extremely fast. Cold starts take seconds, not minutes. Vite's hot module replacement updates components in the browser instantly as you save — no full page reloads, no lost state. The combination of real backend data and sub-second feedback means developers spend their time building features, not waiting on tooling.
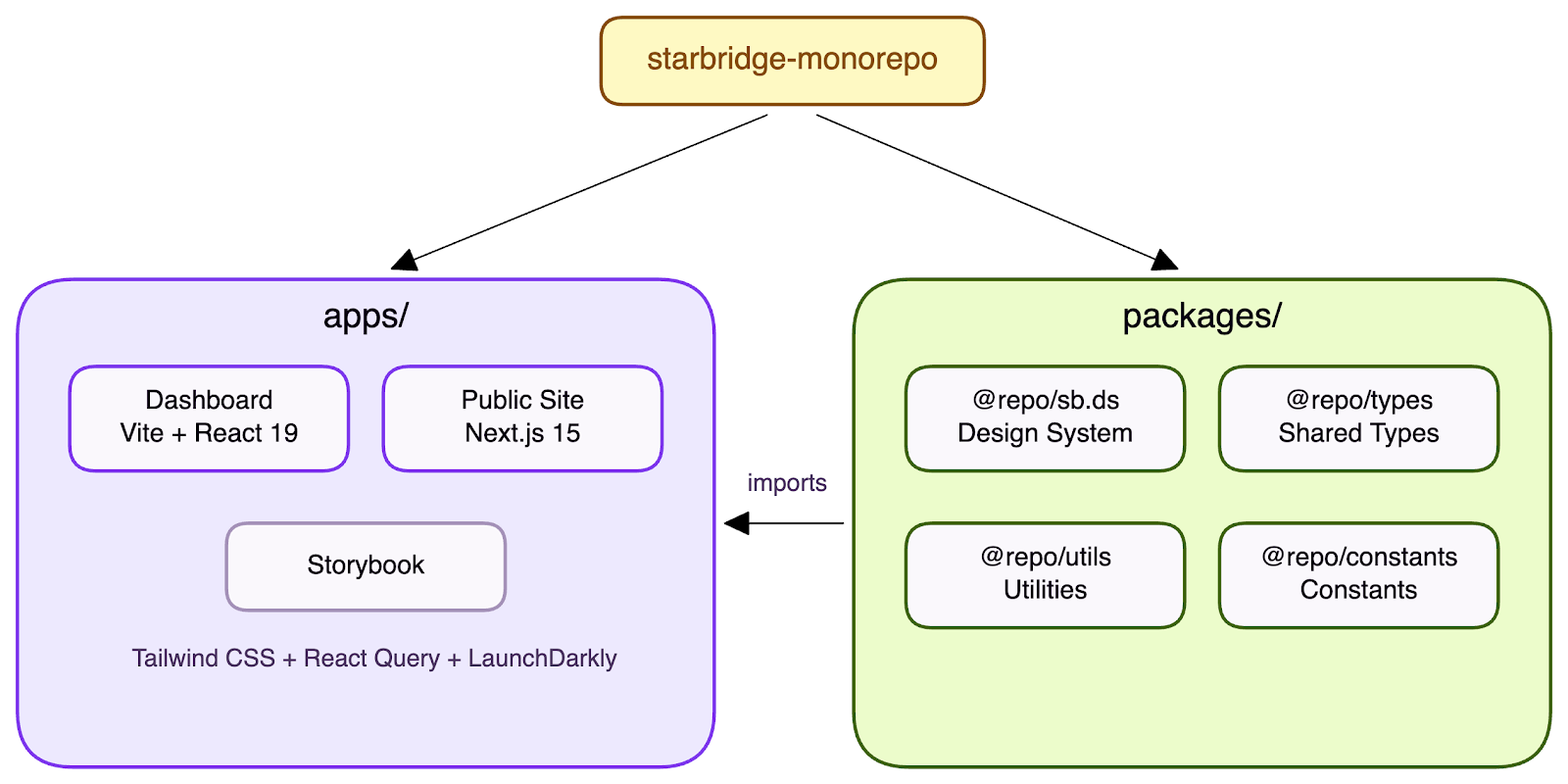
Step 1: Branch, Push, PR
Development starts with a feature branch (feat/ENG-XXXX). Engineers push and open a pull request. CI kicks in immediately.
The PR pipeline runs turbo prepush, which executes ESLint, Vitest tests, and a full build across all affected packages — in parallel. Turborepo schedules each package and app concurrently, so the dashboard build, the public app tests, and the shared library checks all run at the same time. The entire pipeline completes in under 3 minutes for a typical PR.
We have invested heavily in making this pipeline both strict and fast. ESLint and TypeScript run in strict mode — the CI pipeline fails on any violation, so issues are caught at PR time, not in production. Unit tests cover shared utilities, custom hooks, and critical UI components using Vitest with React Testing Library. Turborepo's --filter flag adds precision: a change to @repo/utils triggers tests in both apps, while a change scoped to a single app only runs checks for that app.
Code review is designed to be lightweight. Every PR is automatically reviewed by a Gemini code review agent, which catches common issues and flags potential bugs before a human reviewer even opens the PR. The human review can then focus on architecture, business logic, and edge cases. We require just one approval to merge — the combination of AI pre-review and a single-approval policy eliminates bottlenecks without sacrificing quality.
We also set a high bar for PR descriptions. Every pull request must explain what changed and why, with screenshots or short videos showing the UI impact. This pays for itself immediately — the richer the description, the more context both the AI and human reviewers have to provide targeted feedback instead of going back and forth with clarifying questions.
The result: one PR, one CI run, full confidence that nothing is broken across the monorepo.
Step 2: Deploy to Your Own Environment
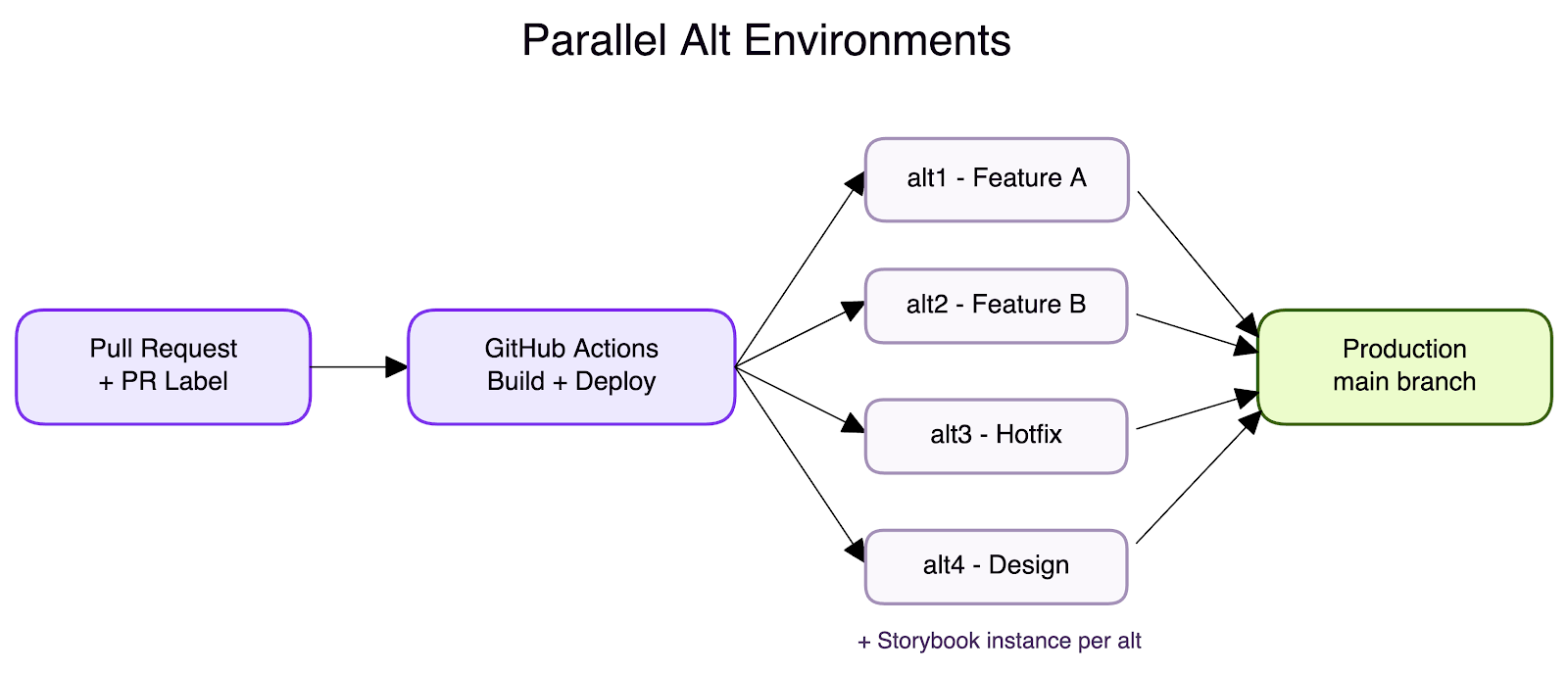
This is the centerpiece of our release process. We maintain many parallel alt environments (alt1 through altN), each backed by its own Cloud Run service. Any engineer can deploy any branch to any available alt environment using one of two methods:
- PR label: Add a label like alt1 or alt3 to your pull request. GitHub Actions picks it up and deploys the branch to that environment automatically. This is the most common method — it is visible to the whole team right on the PR.
- Manual workflow dispatch: Trigger a GitHub Actions workflow, pick an alt number and environment configuration, and deploy. Simple and explicit.
Why does this matter? A single developer can work on multiple features in parallel, each deployed to its own alt environment. But the real power is collaboration — once a feature is deployed to an alt, the engineer shares the URL with QA and the product team for immediate feedback. No waiting for a shared staging slot, no "can you deploy my branch next?" messages. QA validates on alt1 while the developer is already building the next feature on alt2. A product manager reviews a design iteration on alt3 while a hotfix is verified on alt4. Everyone works in parallel, nobody blocks anyone.
For larger features that span multiple developers, an alt environment becomes a shared staging env for the feature branch. Several engineers push to the same branch, deploy it to a dedicated alt, and the entire team — developers, QA, product — tests the integrated result together before it ever touches main. This gives big features the same fast feedback loop that small PRs get, without the overhead of a traditional shared staging environment.
Each alt environment also deploys its own Storybook instance, so designers and reviewers can browse new and updated components in isolation without running the app locally. And because Cloud Run scales to zero when idle, maintaining these environments costs almost nothing.
Step 3: Merge to Main = Ship to Production
Once a feature has been tested in its alt environment and the PR is approved, merging to main triggers an automatic production deployment. The pipeline builds a Docker image, pushes it to the container registry, and deploys to the production Cloud Run service.
Production builds are optimized — they skip Storybook and other development-only artifacts. The deployment is fast and anticlimactic by design. By the time code reaches main, it has already been tested in an isolated environment, reviewed by peers, and validated by CI. Merging is just the final step, not a leap of faith.
Moving Fast with Feature Flags
Alt environments solve the deployment bottleneck, but feature flags solve the coordination bottleneck. We use LaunchDarkly to wrap incomplete or backend-dependent features behind flags, which lets frontend engineers merge and ship code to production even when the backend is not ready yet. The UI stays invisible to users until the flag is enabled. Our React integration uses LaunchDarkly's hook-based subscription model, so components react to flag changes in real time.
This decouples frontend and backend release cycles entirely. A frontend engineer can build a feature against a mocked or partially available API, deploy it behind a flag, and move on. When the backend catches up, flipping the flag enables the feature instantly. And if something breaks in production, disabling the flag is an instant rollback — no code revert needed.
Crucially, flags can be targeted at a specific user or organization. We can enable a feature for a single customer, roll it out to the internal team for dogfooding, or gradually expand to a percentage of users — all without touching code. Feature flags turn releases into independent, low-risk events. Combined with alt environments for pre-merge testing, they let the team move fast without waiting on each other.
Monitoring Production
Shipping fast means nothing if you cannot detect problems quickly. We use Sentry as our real-time alerting system to catch errors the moment they hit production. Sentry captures unhandled exceptions, failed API calls, and performance regressions with full stack traces and session replay context, so engineers can pinpoint the exact commit and code path that caused an issue. Alerts flow into Slack, and because every deployment is tied to a specific PR, tracing a production error back to the change that was introduced takes seconds, not hours. Combined with feature flags for instant rollback, this closes the loop: ship fast, detect fast, fix fast.
What's Next: End-to-End Testing
The one gap in our current pipeline is automated end-to-end testing. Unit tests and strict linting catch a lot, but they cannot verify that a full user flow — login, navigate, submit a form, see the result — works correctly across services. We are actively building an E2E testing layer to close this gap.
The crucial constraint is speed. An E2E suite that takes 20 minutes defeats the purpose of a fast feedback cycle. If developers have to wait too long for results, they stop trusting the pipeline and start merging without it. Our goal is to keep E2E runs fast enough to fit into the same short feedback loop as the rest of CI — so they become a gate developers rely on, not one they route around.
Putting It All Together: A Ticket's Journey to Production
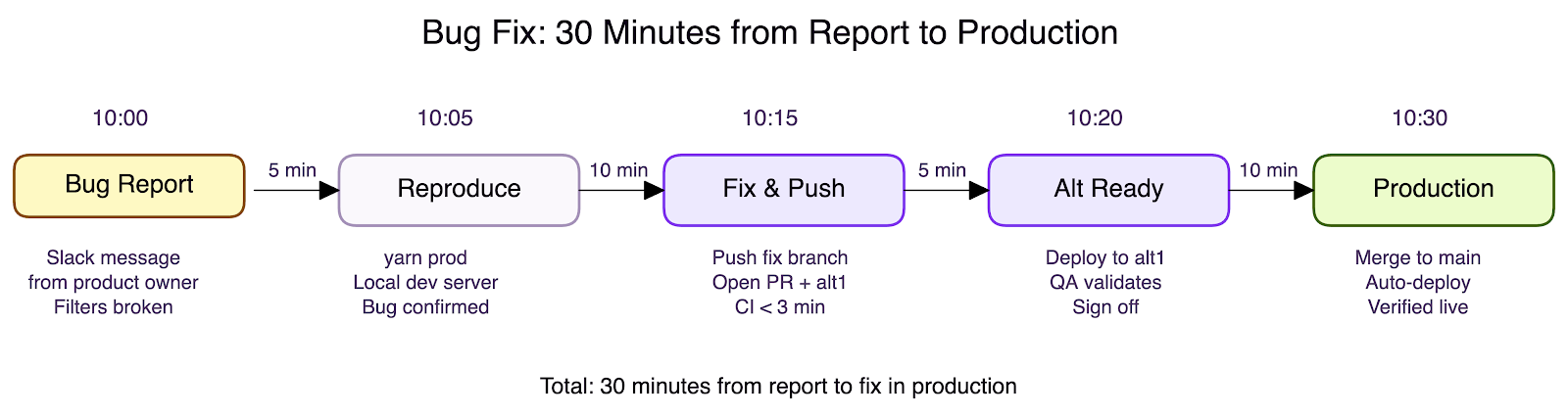
Here is what the process looks like in practice — not a feature but a bug fix reported by the product team. This is where a fast release process earns its keep.
No deployment queue. No environment conflicts. No release ceremony. No rollback needed. The same pipeline that ships features ships fixes — fast, verified, and safe.
This example highlights something most engineering teams struggle with: Definition of Done. In many organizations, "done" is ambiguous — does it mean the code is written? Reviewed? Deployed to staging? Live in production? That ambiguity creates friction with product teams, because when a product owner asks "when will this be released?", nobody can give a straight answer.
Our delivery pipeline collapses that gap. Definition of Done means released to production. When an engineer picks up a ticket, the clock starts. When the fix is live and verified, the clock stops. There is no separate release train, no deploy window, no handoff. The answer to "when will it be released?" is simple: when it is done — and done means shipped.
Is This Process Right for Everyone?
No — and it is important to be honest about that.
We are a startup. Moving fast is a survival requirement, not a preference. The ability to go from idea to production in hours, not weeks, is what lets a small team punch above its weight. But speed has trade-offs.
The code that ships is sometimes raw. Edge cases get handled reactively. Abstractions get deferred. Code that works but is not elegant makes it to production because shipping today matters more than refactoring today. Strict ESLint and TypeScript catch entire categories of bugs at compile time, but strictness in tooling does not replace thoughtfulness in design.
Testing struggles to keep pace. Coverage is solid for shared utilities and critical paths, but feature code often ships with minimal tests because writing them competes directly with building the next feature. The E2E gap we mentioned is a symptom of this tension.
Tech debt accumulates. Fast iterations produce shortcuts, workarounds, and "we will clean this up later" comments. That debt compounds — left unchecked, it slows down the very velocity the process is designed to protect.
This process requires a deliberate balance between shipping fast and maintaining quality — and getting that balance right deserves its own article.
Conclusion
None of this works without the right culture. The tooling removes friction, but it is mature, responsible developers who make the system trustworthy. Every engineer owns their release end to end — from writing the code, to testing it in an alt environment, to watching production after the merge. There is no separate release team, no hand-off, no "someone else will check it." This ownership model only works when developers are confident in what they ship and take accountability for the outcome. The automation gives them the tools to move fast; the discipline ensures they move safely.
Our release process comes down to three properties: isolation, automation, and simplicity. Alt environments give every engineer their own deployment target. GitHub Actions automate the build-deploy cycle end to end. And the merge-to-main-equals-production model keeps the mental overhead low.
Cloud Run's scale-to-zero pricing means we pay only for what we use — eight alt environments cost virtually nothing when idle. The entire system runs on standard GitHub Actions and Google Cloud, with no custom deployment infrastructure to maintain.
The best release process is one that gets out of your way. Push a branch, pick an alt, test it, merge it, ship it. That is it.
Explore our use case library
Ready to give your SLED team real leverage?
Let’s talk about how Starbridge can build a qualified pipeline for your current team — without adding headcount.