.svg)

Build vs. buy: What teams miss about public sector sales data

When teams first consider building an in-house solution to capture public sector buying signals, the pitch sounds reasonable: "We'll just use an LLM to scrape public sector websites and let it find warm opportunities."
In reality, building reliable public sector sales intelligence internally is far more complex than it appears. After spending thousands of hours tackling this problem, our team at Starbridge has seen where even the best technical teams go wrong.
1. The two-part technical challenge
Effective public sector sales intelligence requires solving two distinct problems that most teams underestimate:
Problem 1: Finding the data
Government websites aren't just poorly designed. They're architecturally hostile to modern scraping approaches. Board packets, RFP attachments, and procurement notices are routinely buried 3-4 clicks deep in sites running on legacy CMS systems from the early 2000s.
Unlike consumer websites optimized for search engines and user experience, these sites were built by the lowest bidder with zero consideration for data accessibility. Some render critical documents only after multiple JavaScript executions. Others nest PDFs inside PDFs. Many use frames, redirects, or authentication patterns that break standard crawling logic.
And because you're dealing with 100,000+ individual public sector buyers, there's no universal pattern. A city council in Ohio might publish meeting agendas as Word docs linked from a calendar widget. The same information in California might live in a password-protected board portal, with public excerpts posted as image-based PDFs.
Surface-level scraping or throwing an LLM at the homepage will miss 80%+ of the actionable intelligence. You need purpose-built crawlers that recursively follow links, adapt to site-specific patterns, and maintain state across complex navigation flows.
Problem 2: Making the data actionable
Let's say you solve the scraping problem. You've now got terabytes of unstructured meeting minutes, strategic plans, board packets, and contact data.
Congratulations. You've built a needle-in-a-haystack database that your sales reps will hate.
The hard part isn't collection. It's extraction and delivery. Government documents are not meant for sales intelligence. A 200-page board packet might contain one paragraph about an upcoming IT infrastructure project.
Without sophisticated language models trained specifically on sales intelligence patterns, you'll surface noise. Your reps will waste hours reading irrelevant documents trying to identify whether an opportunity actually exists.
You need models that understand the difference between "exploring options for new student information systems" (early signal) and "approved maintenance contract extension for existing SIS" (not an opportunity). That requires extensive training data, continuous refinement, and deep domain knowledge.
2. The scale challenge
Even if you have the technical chops to solve both problems, there's a third issue: timeliness & maintenance at scale.
You want to see buying signals when they happen, not three weeks later. That means running your scrapers and analysis pipeline across your entire total addressable market on a daily basis, or more frequently for high-priority accounts.
Government websites change constantly. Agencies redesign their sites, move to new CMS platforms, reorganize their information architecture, or change their document hosting. Your scrapers break. Your extraction logic fails. Coverage drops. This isn't a one-time engineering project.
The math gets expensive fast. Running AI agents comprehensively across thousands of government websites daily is either prohibitively costly or you compromise on coverage. Most teams end up choosing: either limited coverage with good latency, or comprehensive coverage with stale data. Neither option works for competitive sales cycles.
We've optimized our infrastructure specifically for this use case. Purpose-built crawlers that know where to look, incremental processing that focuses on what changed, and models trained to extract signals efficiently. Even with those advantages, the compute and orchestration costs are significant.
3. The data you can’t scrape
There's also a category of intelligence that's simply not available through web scraping, no matter how sophisticated your approach.
Purchase order data (the gold standard for understanding what agencies actually buy and when) comes through offline public records requests. It doesn't live on websites. It requires filing requests with individual agencies, navigating varying disclosure processes, and parsing documents that arrive as scanned PDFs or proprietary formats.
This isn't a technical problem you can engineer around. It's a data acquisition problem that requires legal knowledge, persistence, and relationships. Building this capability internally means either hiring people to file and process public records requests at scale, or accepting that you'll never have this intelligence.
The build vs. buy calculation
Building is certainly not impossible. If you have a small TAM & engineering bandwidth, it may be a worthwhile investment.
The question for your team shouldn’t be "Can we build this?" It's "Should we build this?"
If you're a sales team that wants to capture public sector opportunities without becoming an infrastructure company, the build path almost always ends up costing far more than anticipated (in both time and opportunity cost).
Sometimes the smartest technical decision is knowing when a problem deserves a dedicated internal team behind it, and when your energy is better spent elsewhere.
Explore our use case library
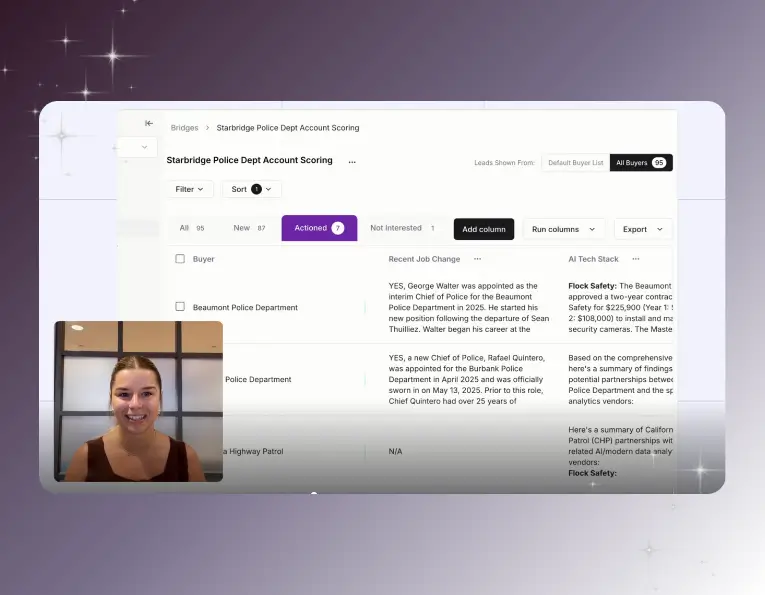
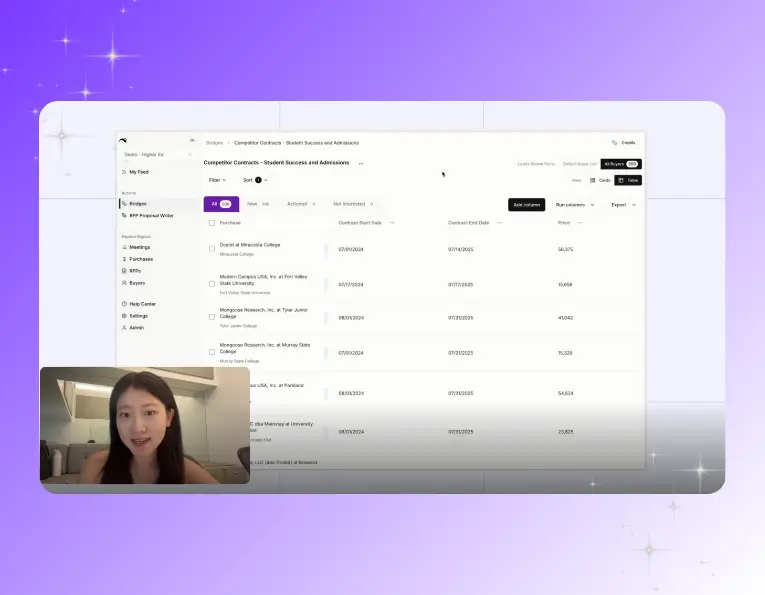
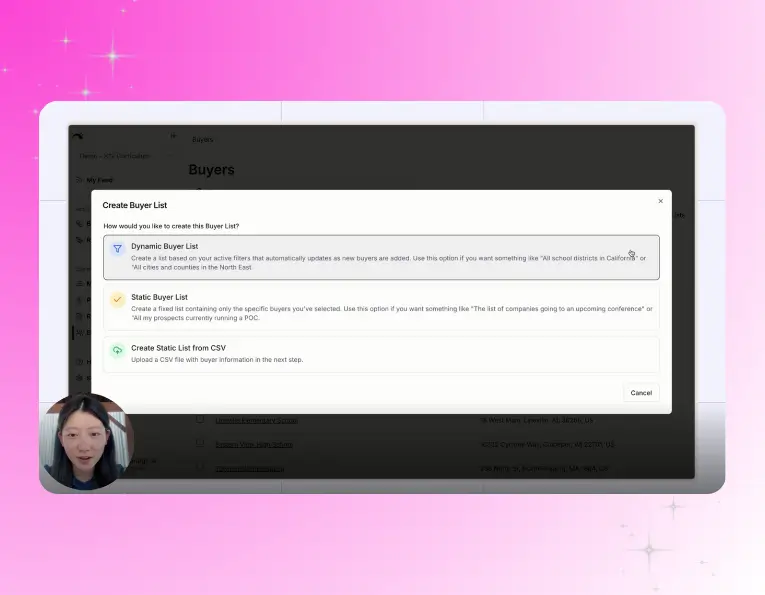
Ready to give your SLED team real leverage?
Let’s talk about how Starbridge can build a qualified pipeline for your current team — without adding headcount.